
- 爱游戏
- 2026-06-29
对话Clipto.AI创始人康洪文:没有记忆的AI,只是一个“失忆”的聪明人
硬件就位,软件缺位
1945年,美国科学家Vannevar Bush在那篇影响了整个计算机科学发展的文章《As We May Think》中,提出过一个名为Memex(记忆延展)的设想。
在他的想象里,每个人都会拥有一台机器。它能够存储自己的阅读、照片、笔记和知识,并像人的记忆一样,随时帮助主人回忆、关联和检索信息——后来,人们把它视作个人计算机、超文本乃至互联网最早的思想源头之一。
Vannevar Bush Memex
过去80年里,计算机、互联网和智能手机相继诞生,存储容量增长了数百万倍,人类积累的信息也以前所未有的速度膨胀。但Bush描绘的那个梦想,却始终没有真正实现。
原因并不复杂。机器越来越擅长保存信息,却始终不会形成记忆;它能存下你一生的数据,却无法在你需要的时候,替你找回某一个瞬间。
直到最近,这件事情开始出现变化。
过去一年,AI行业几乎完成了一次基础设施的集体升级。
端侧算力第一次不再只是概念,而开始成为消费电子产品的标准配置:英伟达推出RTX Spark,将AI算力直接部署至PC;英特尔的Lunar Lake、高通Snapdragon X Elite,将笔记本的NPU算力分别提升至60 TOPS和45 TOPS;苹果也持续将AI能力整合进M系列芯片。
模型也走到了新的拐点。Llama 3、千问、Gemma、Phi等开源模型不断缩小体积,却持续提升能力;llama.cpp、MLX等推理框架的成熟,则让大模型第一次能够稳定运行在普通个人设备上。与此同时,Apple Intelligence、Copilot+ PC,以及英伟达围绕端侧AI搭建的开发工具链,又把模型进一步嵌入操作系统。
芯片、模型、系统,以及随着市场教育,“端侧AI”逐渐赢得用户信任,几乎每一层基础设施都已经准备就绪。
但把这些拼图放在一起,却依然很难得到一款真正让普通用户每天都会使用的AI产品。问题不在于单点技术,而是缺少一个能够把模型、硬件、系统与个人数据真正整合起来的产品。
曾经红极一时的“消费级端侧设备”Rabbit R1、Humane AI Pin,很快因为产品定义失败,成为浪潮中的一捧浮沫。Rabbit R1希望成为一个新的跨端交互入口,然而,它却没能回答“为什么要在手机之外买一台设备”的疑问;Humane AI Pin有替代手机的野心,但酷炫的硬件并不能创造需求,反而带来体验的熵增。
更重要的是,这些端侧新物种,没有解决一个核心痛点:即便处在离用户个人数据库最近的位置,AI大脑仍常常陷入“失忆”的窘态。
行业,缺少一个将模型、端侧和记忆系统整合的玩家。
当所有人都在讨论Agent的时候,一个更底层的问题开始浮现:Agent到底依赖什么长期存在?
两年前,当整个行业仍沉浸在“云端更大的模型”时,Clipto.AI创始人康洪文却做出了一个颇为反共识的判断:
真正的新机会,将出现在端侧算力与大模型能力交汇之后催生的新一层基础设施。
在他看来,只有当两条技术曲线——端侧算力的成熟,以及大模型能力的成熟——同时抵达临界点,AI才有机会真正成为每个人设备里的“第二大脑”,而不仅仅是一个聊天机器人。
而真正的机会,不仅限于模型本身,也属于建立在它们之上的“Memory Layer(记忆层)”。
康洪文和团队研发的产品,Clipto,正是这个假设的试验场。
用户只需要用自然语言描述自己想找的内容,Clipto就能在数TB的本地视频、音频、图片和文档中,快速定位到相关的片段和信息。
但搜索,只是Clipto对外暴露的第一个能力。
在Clipto背后,是由十余个端侧自研大模型、推理架构、算力调度系统,以及数据组织能力共同构建的一套Memory Layer——它让原本分散的海量数据,持续沉淀为可被AI调用的个人记忆,并能够在毫秒内,从海量内容中找回那些早已被用户遗忘的信息。
2026年5月,发布新版Mac端App后,Clipto登上了Product Hunt日榜第一,端侧和记忆构筑的想象空间,正在逐渐落地到田野。

Product Hunt榜首截图
"聪明的人没有记忆,也只是一个失忆的人"
过去一年,Agent成了AI行业最炙手可热的关键词。
几乎所有大模型公司都在讲Agent,创业公司在做Agent,资本追逐Agent。从编程、办公到购物、客服,越来越多的人相信,Agent将成为继ChatGPT之后AI的下一次产品革命。
在2026年4月的报告中,Gartner将业界对Agentic AI的态度形容为达到“期望膨胀顶峰(the Peak of Inflated Expectations)”,超过六成企业计划在未来两年部署AI Agent,即便迄今为止,只有17%的企业完成了部署。
但在这场几乎没有异议的追捧中,Clipto创始人康洪文却不断提出一个看似简单、却很少有人回答的问题:一个没有记忆的Agent,真的理解用户吗?
在他看来,今天大多数Agent都建立在一个危险的假设之上:只要模型足够聪明,就能够成为用户的助手。
但事实恰恰相反。每一次打开Agent,它都像第一次认识你;不知道你昨天开过什么会,不知道你的照片存在哪里,也不知道过去一年积累了哪些文档。它能够推理,却没有经历;能够回答,却无法延续。
“一个聪明的人,如果没有记忆,也只是一个失忆的人。”康洪文说。
这也是他过去二十多年一直在研究的问题。
开始的前十年,康洪文的研究命题是机器如何理解世界。2004年,康洪文进入微软亚洲研究院实习,让Xbox自动分析用户拍摄的大量家庭照片和视频,再从数小时素材中提取关键片段,自动生成一段家庭短片。
而后,他前往卡内基梅隆大学机器人研究所攻读博士,师从计算机视觉领域学者Takeo Kanade,继续研究图像与视频理解。在他看来,理解视频,本质上是在理解现实世界。
最近的十年,康洪文转向研究机器如何生成内容。2017年,他创业成立AIGC公司“慧川智能”,随后旗下创作平台“智影”在2020年底被腾讯收购。加入腾讯后,康洪文继续负责文生图、文生视频和数字人等全栈AIGC产品研发。
而今天,在Clipto,康洪文又把问题重新拉回了”理解”。因为他认为,生成已经不是AI最大的瓶颈,“真正缺失的是记忆”。
端侧大模型的出现,让这条技术路线第一次迎来了成熟的时机。

康洪文告诉36氪,云端模型更像是一个“全球大脑”,负责学习公共知识、理解整个世界;而端侧AI则应该成为“个人记忆”,理解的是每一个具体的人。
在他看来,未来AI的架构并不会是Cloud AI与Edge AI的简单竞争。真正的演化方向是Cloud Intelligence + Edge Memory——云端负责世界知识,端侧负责个人记忆,Agent 只是连接两者的交互层。
“Agent只是站在最上层的交互界面,而真正决定它是否聪明的,并不只是模型本身,而是底下是否拥有一套持续生长的Memory Layer(记忆层)。”他提到,在他看来,这是一个被行业长期忽视的架构问题。
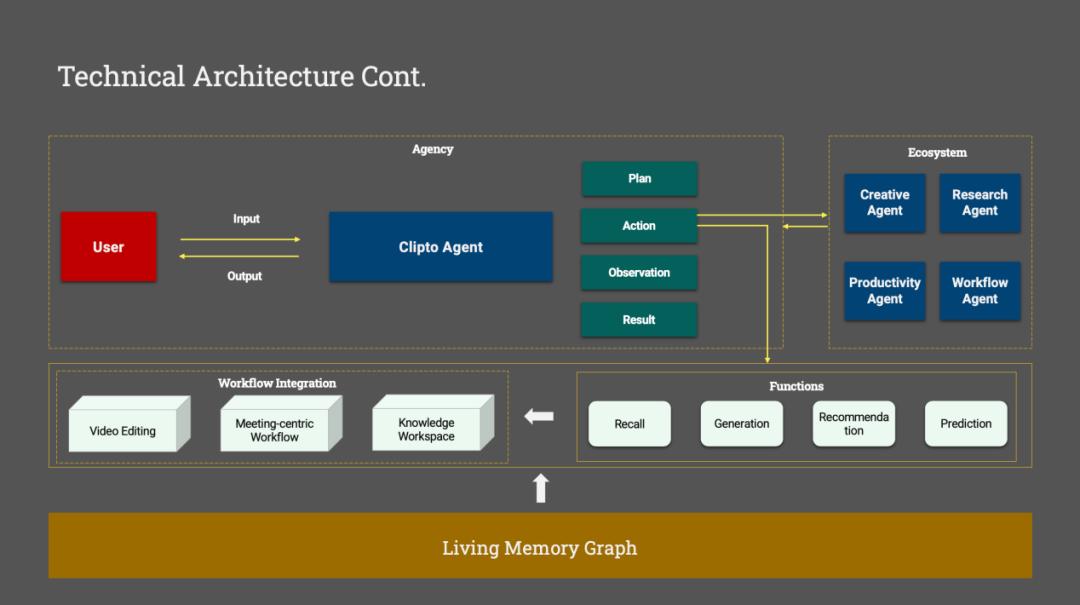
Living Memory Graph
模型会升级,Agent会重构,但用户长期积累的记忆不会轻易迁移。他提到。
围绕“记忆层”,Clipto从底层重新搭建了一整套端侧AI技术体系。
在康洪文看来,很多人理解的Memory,更像是模型拥有更长的Context,或者接入一个向量数据库。但真正的记忆层,远不止于此。
"Memory不是一个模型,而是一整套系统。"他在采访中提到。
第一层,是模型。
多模态数据天然具有高度异构性。视频、音频、图片、文档,每一种数据都需要不同的理解方式。围绕人物识别、语音理解、OCR、场景分析、事件理解等能力,Clipto自研了十余个端侧AI模型,其中部分基于开源基础模型进行针对性的后训练,部分则完全自主研发。每一个模型都需要针对端侧算力重新设计,而不是直接迁移云端模型。
第二层,是端侧算力架构。
与云端拥有几乎无限算力不同,端侧设备受到CPU、GPU、NPU、内存、存储带宽以及系统资源的共同限制。为了让多个模型能够长期协同工作,Clipto从零搭建了端侧推理框架和算力调度系统,根据设备资源动态调度不同模型,而不是让它们彼此争抢计算资源。
康洪文介绍,Clipto的架构能够自动兼容各种不同配置的设备,甚至包括仅配备8GB内存的M1 MacBook。而在最新一代的M5 MacBook Pro上,Clipto可在24小时左右完成2TB本地视频的离线分析,如果完全依赖云端,同样的处理成本约需400美元。
用户使用Clipto制作视频电脑桌面截屏
第三层,也是最重要的一层,构建记忆本身。
模型能够理解内容,却不会天然形成记忆。系统还需要持续把分散的多模态信息组织成时间、地点、人物、事件等结构化关系,并不断建立跨文件、跨时间、跨来源之间的关联,最终形成能够持续生长的个人记忆网络。
Agent调用的,也不再是某一个模型,而是这套不断积累、持续演化的记忆层。
在康洪文看来,这也是记忆层真正困难的地方。
它横跨模型研发、端侧推理、算力调度、多模态理解、数据组织、时空数据库、知识图谱以及检索系统等多个技术层级。任何一个模块都无法单独构成真正的Memory。只有把这些能力整合成一套长期运行、持续生长的系统,AI才真正拥有了"记忆"。
"模型会不断升级,Agent也会不断演进,但用户长期积累的记忆不会轻易迁移。真正的护城河,是围绕Memory建立起来的整套技术体系。"他对36氪总结。
如果说今天的大模型解决的是AI如何理解世界,那么Clipto解决的是AI如何长期记住一个人。
Clipto不是创作工具,而是记忆基础设施
Clipto登顶Product Hunt日榜后,真正让康洪文感到意外的不是成绩本身,而是评论区的用户反馈。
按照惯例,大多数用户讨论的是产品好不好用、功能是否足够丰富。但Clipto上线后,评论区里出现了另一种声音:
不少开发者开始询问API是否开放、能否作为Agent的长期记忆后端,甚至讨论如何把Clipto接入自己的产品——彼时,Clipto甚至还没有发布SDK。
这释放出一个信号:用户关注的已经不只是一个搜索工具,而是开始把它视作一层基础设施。
这种变化,也超出了Clipto团队最初的预期。
一开始,康洪文以为最先买单的会是视频创作者、摄影师等内容生产者。但随着用户增长,团队发现,快速扩大的不仅是创作者群体,还包括金融分析师、律师、医生、咨询顾问等知识工作者。
根据官方数据,目前,Clipto的用户中,大约1/3为创作者,其余2/3则是来自金融、法律、医疗等行业的专业职场人。
这意味着,记忆管理,是比内容创作空间更大、更刚性的需求。
过去,人们总认为多模态数据管理是视频编辑、影视制作等专业场景才需要解决的问题。事实上,每一个知识工作者都在不断产生音频、图片、会议记录和文档。会议录音、培训视频、手机截图、播客收藏、PDF文件……这些信息每天都在增长,却很少能够再次被有效调用。
当AI能够真正理解这些数据之后,“记忆管理”便不再是创作者的需求,而成为所有人的需求。
商业数据进一步验证了这一判断。Clipto上线后三个月,便实现了盈亏平衡。2025年,公司的ARR(年度经常性收入)达到了1500万美元。
对于一家仍处于产品早期、且坚持端侧部署路线的AI公司而言,这样的商业化速度本身就是一个强信号:市场愿意付费的,并不仅仅是一次性的AI能力,而是长期积累的个人记忆。Memory并不是一个未来市场,而是一个已经被验证的现实需求。
更重要的是,它也验证了Clipto团队的能力。当许多AI创业公司仍停留在模型能力验证或Demo阶段时,Clipto已经率先完成了从底层模型、端侧基础设施、产品体验到商业化的完整闭环。这种跨越底层研发、产品设计和全球商业化的完整执行能力,本身就是团队最重要的竞争壁垒。
互联网的发展史,本质上是一部基础设施不断演进的历史。
PC互联网时代,Google建立了信息检索的基础设施,它建立的是人类的公共记忆(Collective Memory),让人们能够"找到世界上的信息";移动互联网时代,Meta和微信构建了社交关系的基础设施,让人们能够"连接世界上的人";AI时代,OpenAI解决了"如何推理"的问题,而接下来即将面临的,不再是"世界知道什么",而是"我自己经历了什么",让人们能够"被AI真正理解"。
这正是下一代基础设施的机会。
Clipto希望解决的,正是每个人的个人记忆(Personal Memory)。
它并不创造新的内容,而是持续理解、组织和连接用户过去积累的数字生活,让这些原本沉睡的数据,成为Agent可以长期调用的上下文。
也因此,在康洪文看来,未来AI应用真正的竞争,并不只是模型能力,也不只是Agent的执行能力,而是谁能够率先建立起这层长期存在的Memory Layer。
“模型可以随时切换,Agent也可以重构,但用户长期积累的记忆一旦形成,迁移成本极高。”
过去十年,AI公司争夺的是Intelligence;未来十年,真正不可替代、也最难迁移的,将是Memory。

Clipto.AI创始人康洪文
围绕Clipto的构想、端侧AI、记忆层,36氪近期和Clipto.AI创始人康洪文聊了聊。以下是我们对部分观点的整理:
36氪:Clipto为什么从音视频搜索切入?
康洪文:有两个考虑。
首先,文本、文件、PPT数据已有不错方案,但音视频这种重多模态的数据一直没被服务好,单位处理成本高;
其次,音视频天然更多存在端上(太重),完美贴合端侧优先场景。种子用户=有大量音视频、高隐私高价值、现有方案服务不好的人。
36氪:Clipto的PMF为什么跑得快?做对了什么?
康洪文:"以终为始",我们有宏大的愿景,但还是要逼自己尽快做商业化验证。
我们做了两个关键决策。首先,以App形态切入,将端侧AI的能力最高效送到用户手里;未来,App也可以灵活搭载在PC、手机、智能设备等任何终端硬件上。
其次,第一天就主打全球市场。不少西方国家用户支付订阅习惯成熟,确定性高。我们选择把精力放在高确定性的事上。
36氪:行业对端侧AI最大的误解是什么?
康洪文:“下个Ollama就能做。”
但我们真正做的,其实是一整套Memory Layer。
第一层,是模型。围绕多模态理解,我们已经自研了十余个端侧AI模型,其中部分基于开源基础模型进行后训练,部分完全自主研发。真正做到专业级、多模态理解,本身就是非常大的技术挑战。
第二层,是基础设施。端侧和云端几乎是两套完全不同的技术体系。从推理框架、算力调度到系统优化,都需要重新设计,让多个模型能够在有限的设备资源下长期稳定协同运行。
第三层,是记忆构建。模型能够理解内容,但不会天然形成记忆。系统不仅需要理解每一个文件,更需要持续建立跨文件、跨时间、跨来源之间的关联,把原本孤立的数据组织成一个能够不断生长的个人记忆网络。
真正困难的,并不是某一层技术,而是把模型、基础设施和记忆构建长期协同成一套系统。这也是我们认为Memory Layer真正的技术门槛。
36氪:Clipto定义的"记忆"和模型记忆、Context有何区别?
康洪文:
今天行业里讲的“Memory”,其实主要有两种。
一种是模型记忆,它本质上是参数里的统计性知识,更适合学习公共知识、用户偏好和行为模式。
另一种是Context,它解决的是一次任务里的短期上下文,帮助模型完成当前对话,但生命周期很短。
Clipto做的是第三种记忆。
我们关注的是用户长期积累的真实个人数据,包括视频、音频、图片、文档和会议记录。这些数据不是抽象概念,而是一个人真实经历和工作的完整沉淀。
举个例子,模型可能知道你最近一直在讨论产品定价,也知道你更关注欧美市场,这是统计性的”记忆”。但它永远不可能准确回答:“5月18日下午那场融资会议里,John对欧洲定价策略到底说了什么?”
因为这些具体、可追溯的事实,不应该被编码进模型参数,而应该作为个人记忆长期保存,并能够随时被AI精准调用。
所以我们认为,模型负责学习公共知识,Memory Layer负责保存个人知识。
36氪:记忆层会被模型厂商吃掉吗?
康洪文:
我觉得不会。
我一直认为,未来AI会逐渐形成新的分工。
模型负责Intelligence,持续学习和编码公共知识;Memory Layer则负责保存和组织每个人独有的长期记忆。
这两者解决的是完全不同的问题。
模型的价值来自规模化,服务的是所有用户;Memory Layer的价值来自个性化,它需要持续理解、组织和管理每一个人的数据。
所以模型厂商未必天然擅长做Memory Layer,就像Google很擅长搜索,但并没有天然解决个人记忆的问题一样。
我们更相信,未来Agent会不断变化,模型也会不断升级,但Memory Layer会成为长期存在的一层基础设施。
封面来源|视觉中国

2 条评论
一手掌握最新游戏动态。
与全球玩家深度交流。